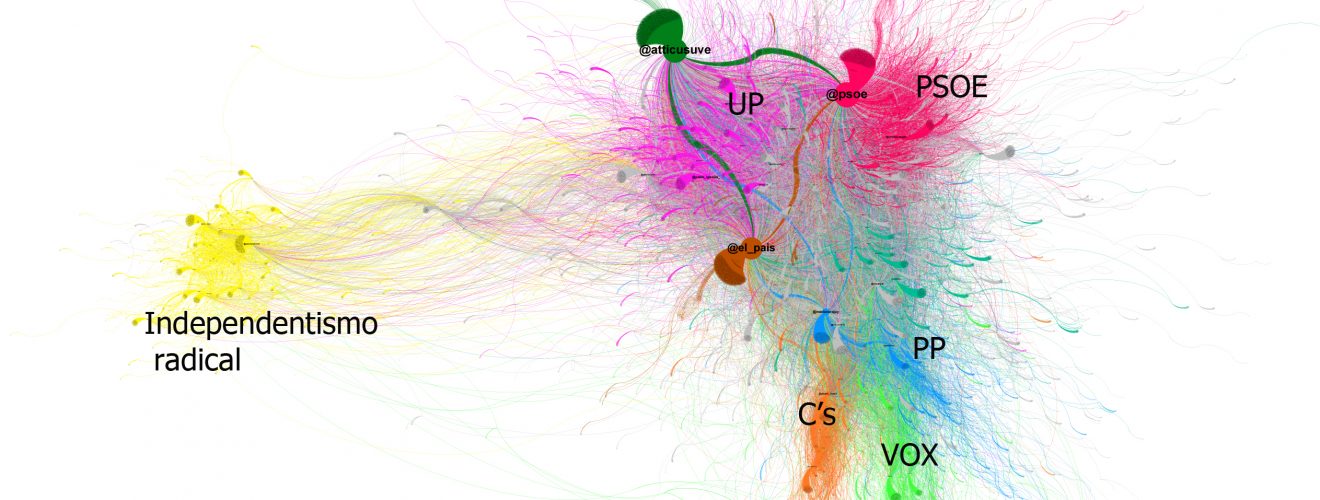
0 Twitter junio 7, 2019 por Mariluz Congosto · Published junio 7, 2019 · Last modified junio 25, 2019 Explicando los detalles de un grafo
0 Twitter junio 7, 2019 por Mariluz Congosto · Published junio 7, 2019 Fuentes digitales: un caso de estudio sobre la recuperación de la Memoria Histórica
0 Twitter junio 7, 2019 por Mariluz Congosto · Published junio 7, 2019 Nadie es lo que parece en Twitter: el pasado de @superwomanroja
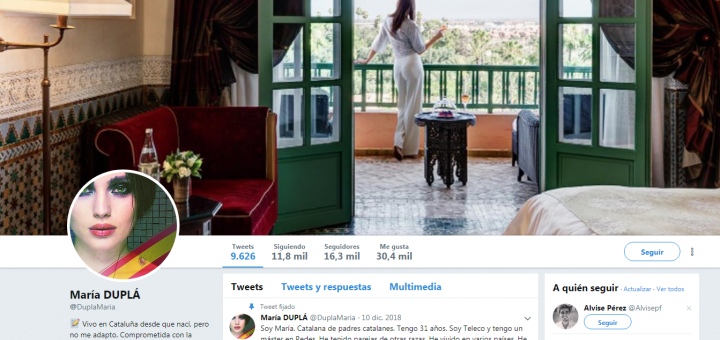
0 Twitter junio 7, 2019 por Mariluz Congosto · Published junio 7, 2019 @DuplaMaria, un astroturfing de libro
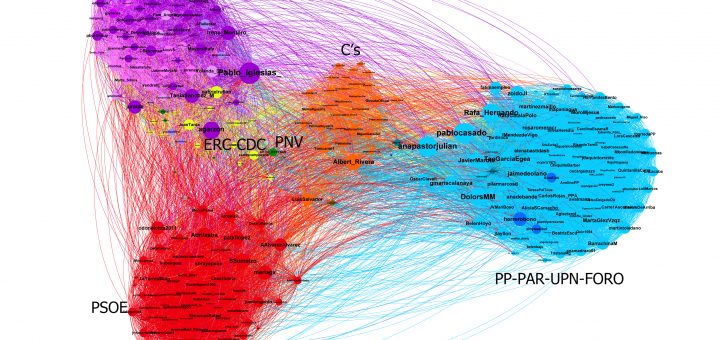
0 Twitter junio 7, 2019 por Mariluz Congosto · Published junio 7, 2019 Conexiones de los diputados de la XII legislatura
0 Twitter diciembre 26, 2018 por Mariluz Congosto · Published diciembre 26, 2018 El bulo de la excarcelación de Miguel Carcaño
0 Hilo / Twitter diciembre 26, 2018 por Mariluz Congosto · Published diciembre 26, 2018 El bulo del musulmán atacando a personal médico